
Amazon S3 Tables と Iceberg Tables on Amazon S3 のパフォーマンス比較 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。
この記事は AWS Analytics Advent Calendar 2024 の 22 日目の記事です。
Amazon S3 Tables は、「クエリパフォーマンスが最大 3 倍高速になり、1 秒あたりのトランザクション数が最大 10 倍」と言われています。本日は、「Amazon S3 Tables vs Iceberg Tables on Amazon S3 」と題して、パフォーマンスを比較したいと思います。
どのようなクエリが速くなるのか
具体的にどのようなクエリが速くなるのかについて考察します。
セルフマネージドテーブルストレージと比較すると、クエリパフォーマンスが最大 3 倍高速になり、1 秒あたりのトランザクション数が最大 10 倍になる
引用: Amazon Web Services ブログ の Amazon S3 の新しいテーブル: 分析ワークロードのために最適化されたストレージより
小さなファイルの問題解決
S3 Tablesは自動的にファイルの圧縮(compaction)を行うため、小さなParquetファイルが多数存在する環境で特に効果を発揮します。
- 範囲スキャンを伴うクエリ
- インデックスを使用しないフルスキャンクエリ
つまり、自動的にファイルの圧縮(compaction)する仕組みを標準で導入することによって、そもそもファイル数が多くならないような仕組みを備えています。
トランザクション処理の向上
S3 Tablesは1秒あたりのトランザクション数(TPS)を最大10倍に向上させています。
- 頻繁な更新や挿入を行うクエリ
- ストリーミングデータの取り込み
- 変更データキャプチャ(CDC)ワークロード
などのパフォーマンスが向上します。
上記のような小さなファイル更新が頻発するようなユースケースにおいて、最新のファイルの圧縮(compaction)ができない場合でもパフォーマンス低下を軽減する仕組みを備えています。
では、具体的にどのような違いがあるのかを解説します。
S3 TablesとS3の汎用バケットとの違い
S3 Tablesを使用すると、汎用バケット内のプレフィックスと比較して、最初から1秒あたりのトランザクション数(TPS)が最大10倍に向上します。これに加えて、バックグラウンドで定期的に実行される自動圧縮(compaction)機能によってデータファイルが統合されるため、S3 Tables上にIcebergテーブルを保存する際のクエリパフォーマンスが最大3倍速くなります。
S3 Tablesは表形式データに特化して設計されています。つまり、アプリケーションがIceberg標準を使用してこれらのテーブルにデータを読み書きする一方で、S3はIceberg形式で保存されているこれらの表形式データセットを認識し、特定の最適化を適用できるのです。これは、名前が示すように様々なワークロードに一般的に使用される汎用バケットとは対照的です。
内部的には、S3のnamespaceを調整してデータをより最適化された方法で配置することで、アプリケーションが最初から高いTPSを達成できるようになっています。比較のために、汎用バケットのプレフィックスでは、1秒あたり5,500回の読み取りまたは3,500回の書き込みから始まります。これは単なる出発点であり、リクエストトラフィックの需要が増加し、バケットへのトラフィックが増えるにつれて、S3は自動的にその負荷下でリクエスト容量を追加し、追加の需要に対応できるようにします。

対照的に、Table Bucketでは、最初から1秒あたり55,000回の読み取りまたは35,000回の書き込みという、最大10倍のTPSを期待できます。そしてそれ以上にスケールし続けます。ここでは、Icebergに特定の最適化を提供しており、データを書き込み、データファイルを配置するデフォルトの方法が、S3が提供する自動スケーリングを活用できるように最適化されています。
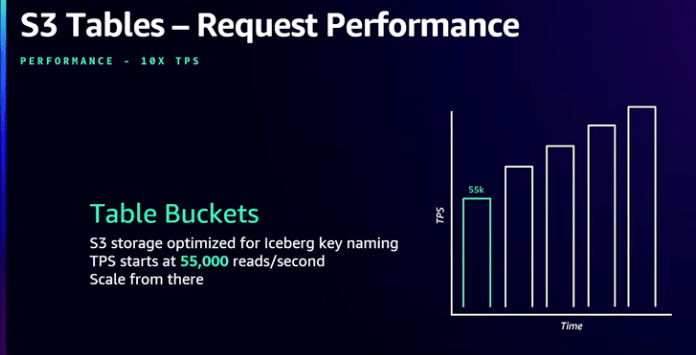
引用: AWS re:Invent 2024 - [NEW LAUNCH] Store tabular data at scale with Amazon S3 Tables (STG367-NEW)
AWS Storage Blogで発表されたベンチマーク結果によると、TPC-DSクエリセットを使用した実験で、以下のようなクエリで大幅な性能向上が見られました。
| A | B | C | D | |
|---|---|---|---|---|
| 1 | TPC-DS Query ID |
Uncompacted table in general purpose bucket(seconds) | Compacted table in table bucket(seconds) | Performance improvements |
| 2 | 25 | 51.8 | 46.39 | 1.12x |
| 3 | 31 | 117.21 | 45.24 | 2.59x |
| 4 | 49 | 134.51 | 60.43 | 2.23x |
| 5 | 76 | 45.61 | 19.84 | 2.3x |
| 6 | 77 | 55.79 | 19.91 | 2.8x |
| 7 | 80 | 62.96 | 40.56 | 1.55x |
| 8 | 88 | 180.94 | 56.2 | 3.22x |
| 9 | 96 | 23.63 | 8.34 | 2.83x |
| 10 | Total runtime | 672.46 | 296.92 | 2.26x |
Table 1: Query avg. runtime (in seconds) across repeated runs
引用: How Amazon S3 Tables use compaction to improve query performance by up to 3 times
これらのクエリは複雑な分析や集計を含むものが多く、S3 Tablesの最適化の恩恵を受けやすいと考えられます。
検証の準備
S3 Tables と Glue Data Catalog の違い
従来のGlue Data Catalogでは、Noneですが、S3 Tablesでは、Table Bucket名になります。従来のGlue Data Catalogのデータベース名の代わりに、S3 Tablesでは、namespaceになります。
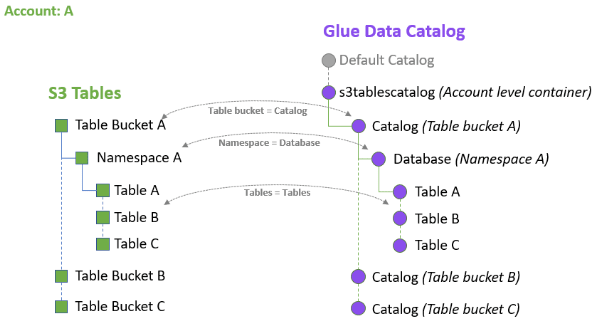
そのため、AthenaやGlueからS3 Tables上のテーブルにアクセスするには、<catalog>.<namespce>.<table>の順でテーブルを指定します。具体例を以下に示します。
"s3tablescatalog/cm-namespace-20241222"."cm_namespace"."lineorder"
検証の方針
小さなファイルが多数存在するアンチパターンな環境を再現してテストするよりも、一般的なワークロードのようにデータをコピーして、集計するといった一般的なユースケースで検証を進めます。
データロードはAWS Glue、データ参照はAmazon Athenaを用います。
データロード時間の検証
テーブルを削除した後、テーブルを作成して、データをロードしたコードを作成しました。テーブルを削除する際にはファイルのクリーンナップ、テーブルを作成してデータをロードすると、それぞれ多くの操作が必要と考えたからです。
Amazon S3 Tablesの検測用コード
S3 Tables上に作成したテーブルの検証用のコードです。下記のコードを5回実行して計測しました。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# sc = SparkContext()
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
def build_spark_session_s3t(namespace, warehouse_arn):
spark = SparkSession.builder \
.config(f"spark.sql.catalog.{namespace}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{namespace}.warehouse", warehouse_arn) \
.config(f"spark.sql.catalog.{namespace}.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
return(spark)
TARGET_DATE = '1992-10-01'
TARGET_START_DATE = TARGET_DATE
TARGET_END_DATE = '1992-10-31'
# Create Spark Session for S3 Tables
warehouse_arn = "arn:aws:s3tables:us-east-1:123456789012:bucket/cm-namespace-20241222"
spark_s3t = build_spark_session_s3t("s3tablesbucket", warehouse_arn)
# Dynamic Frame from catalog
partition_predicate = f"lo_orderdate between '{TARGET_START_DATE}' and '{TARGET_END_DATE}'"
lineorder_p = glueContext.create_dynamic_frame.from_catalog(
database="ssb",
table_name="lineorder_p",
push_down_predicate = partition_predicate,
transformation_ctx="lineorder_p",
)
# lineorder_p.printSchema()
df = lineorder_p.toDF()
# df.printSchema()
# df.show()
# print(df.count())
# # Create namespace in S3 Tables
# spark_s3t.sql(""" CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.cm_namespace """)
spark_s3t.sql("""
DROP TABLE IF EXISTS s3tablesbucket.cm_namespace.`lineorder` PURGE
""")
spark_s3t.sql("""
CREATE TABLE IF NOT EXISTS s3tablesbucket.cm_namespace.`lineorder` (
`lo_orderkey` int,
`lo_linenumber` int,
`lo_custkey` int,
`lo_partkey` int,
`lo_suppkey` int,
`lo_orderpriority` string,
`lo_shippriority` string,
`lo_quantity` int,
`lo_extendedprice` int,
`lo_ordertotalprice` int,
`lo_discount` int,
`lo_revenue` int,
`lo_supplycost` int,
`lo_tax` int,
`lo_commitdate` string,
`lo_shipmode` string,
`lo_orderdate` string
) USING iceberg
PARTITIONED BY (`lo_orderdate`)
""")
# # Use Namespace
# spark_s3t.sql(""" USE s3tablesbucket.cm_namespace """)
# # Show Tables
# spark_s3t.sql(""" SHOW TABLES """).show()
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_lineorder")
spark_s3t.sql("""
INSERT INTO s3tablesbucket.cm_namespace.`lineorder`
SELECT * FROM tmp_lineorder
""")
Iceberg Tables on Amazon S3の計測用コード
S3上にIcebergフォーマットのGlueテーブルの検証用のコードです。下記のコードを5回実行して計測しました。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# sc = SparkContext()
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
def build_spark_session_s3i(catalog_name, warehouse_path):
spark = SparkSession.builder \
.config("spark.sql.warehouse.dir", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.warehouse", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
return(spark)
TARGET_DATE = '1992-10-01'
TARGET_START_DATE = TARGET_DATE
TARGET_END_DATE = '1992-10-31'
# Create Spark Session for Iceberg Tables on Glue
i_catalog_name = "glue_catalog"
i_bucket_name = "cm-datalaker-20241222"
i_bucket_prefix = "lineorder"
i_database_name = "ssb_iceberg"
i_table_name = "lineorder"
i_warehouse_path = f"s3://{i_bucket_name}/{i_bucket_prefix}"
spark_s3t = build_spark_session_s3i(i_catalog_name, i_warehouse_path)
# Dynamic Frame from catalog
partition_predicate = f"lo_orderdate between '{TARGET_START_DATE}' and '{TARGET_END_DATE}'"
lineorder_p = glueContext.create_dynamic_frame.from_catalog(
database="ssb",
table_name="lineorder_p",
push_down_predicate = partition_predicate,
transformation_ctx="lineorder_p",
)
# lineorder_p.printSchema()
df = lineorder_p.toDF()
# df.printSchema()
# df.show()
# print(df.count())
spark_s3t.sql(f"""
DROP TABLE IF EXISTS {i_catalog_name}.{i_database_name}.{i_table_name} PURGE
""")
spark_s3t.sql(f"""
CREATE TABLE IF NOT EXISTS {i_catalog_name}.{i_database_name}.{i_table_name} (
`lo_orderkey` int,
`lo_linenumber` int,
`lo_custkey` int,
`lo_partkey` int,
`lo_suppkey` int,
`lo_orderpriority` string,
`lo_shippriority` string,
`lo_quantity` int,
`lo_extendedprice` int,
`lo_ordertotalprice` int,
`lo_discount` int,
`lo_revenue` int,
`lo_supplycost` int,
`lo_tax` int,
`lo_commitdate` string,
`lo_shipmode` string,
`lo_orderdate` string
) USING iceberg
PARTITIONED BY (`lo_orderdate`)
""")
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_lineorder")
spark_s3t.sql(f"""
INSERT INTO {i_catalog_name}.{i_database_name}.{i_table_name}
SELECT * FROM tmp_lineorder
""")
検証結果
同じ条件でAWS Glue実行しても実行時間の差が大きく見られます。5回実行した平均値を見ると、大きな差は現れませんでした。
| 1st | 2nd | 3rd | 4th | 5th | ave | |
|---|---|---|---|---|---|---|
| Amazon S3 Tables | 231 | 245 | 200 | 259 | 259 | 238.8 |
| Iceberg Tables on Amazon S3 | 237 | 226 | 219 | 246 | 227 | 231 |
※ 単位: 秒
クエリ時間の検証
Amazon Athenaからテーブルの結合、集計、ソートを含むクエリを実行しました。
Amazon S3 Tablesの検測用コード
下記のSQLを5回実行して計測しました。
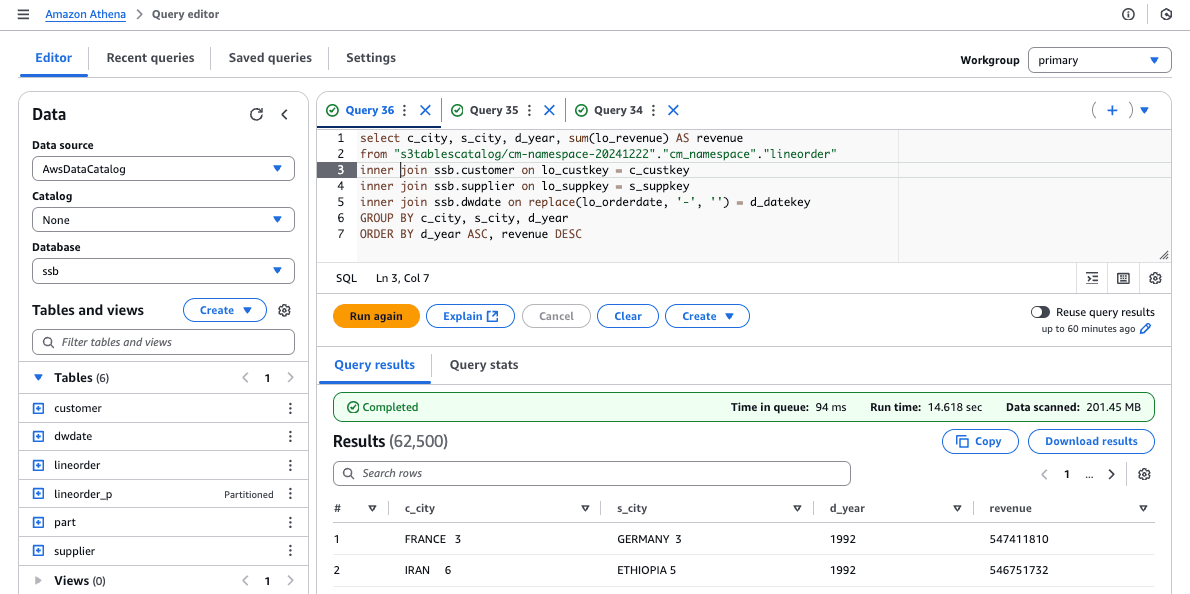
select c_city, s_city, d_year, sum(lo_revenue) AS revenue
from "s3tablescatalog/cm-namespace-20241222"."cm_namespace"."lineorder"
inner join ssb.customer on lo_custkey = c_custkey
inner join ssb.supplier on lo_suppkey = s_suppkey
inner join ssb.dwdate on replace(lo_orderdate, '-', '') = d_datekey
GROUP BY c_city, s_city, d_year
ORDER BY d_year ASC, revenue DESC
Iceberg Tables on Amazon S3の計測用コード
下記のSQLを5回実行して計測しました。
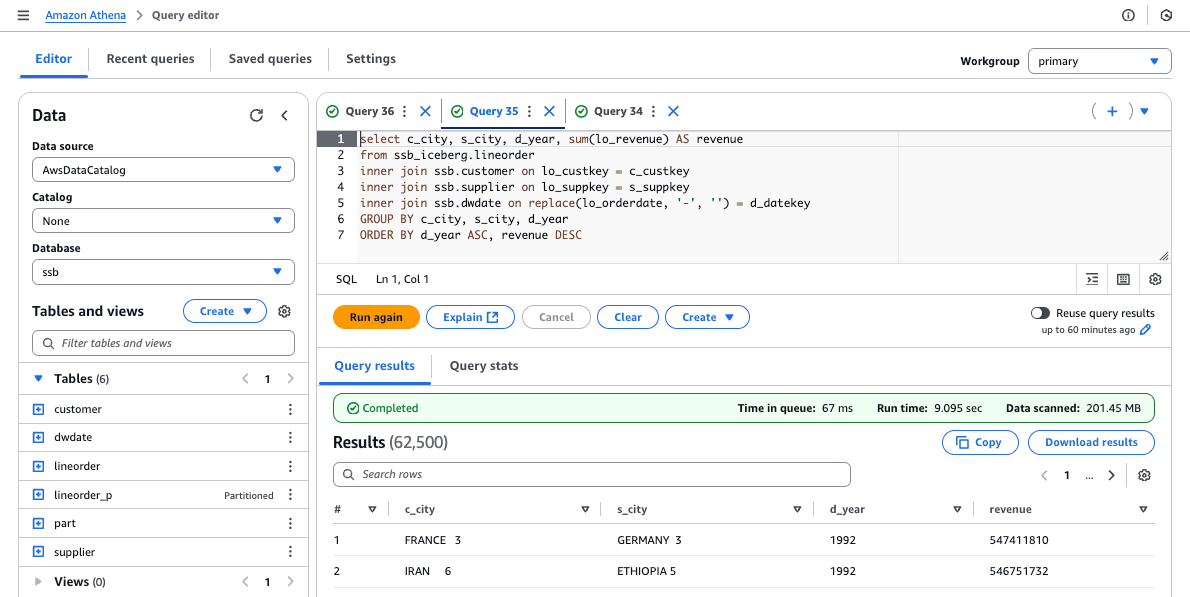
select c_city, s_city, d_year, sum(lo_revenue) AS revenue
from ssb_iceberg.lineorder
inner join ssb.customer on lo_custkey = c_custkey
inner join ssb.supplier on lo_suppkey = s_suppkey
inner join ssb.dwdate on replace(lo_orderdate, '-', '') = d_datekey
GROUP BY c_city, s_city, d_year
ORDER BY d_year ASC, revenue DESC
検証結果
S3 Tablesの方が明らかに遅くなりました。これは以前から感じたことですが、Amazon Athenaからクエリを実行すると、平均5秒ほどのオーバーヘッドがあるように感じます。
| 1st | 2nd | 3rd | 4th | 5th | ave | |
|---|---|---|---|---|---|---|
| Amazon S3 Tables | 14.618 | 14.639 | 14.888 | 15.111 | 15.657 | 14.9826 |
| Iceberg Tables on Amazon S3 | 9.095 | 7.231 | 9.227 | 7.659 | 8.023 | 8.247 |
※ 単位: 秒
最後に
今回の検証結果では、残念ながら Amazon S3 Tablesとアナリティクスサービスの組み合わせでは期待されていたほどのパフォーマンス向上を示されませんでした。データロード時間においては、S3 TablesとIceberg Tables on Amazon S3の間に大きな差は見られませんでした。クエリ実行時間では、予想に反してS3 Tablesの方が遅くなる結果となりました。
これらの結果は、S3 Tablesが特定のワークロードや使用シナリオに最適化されている可能性を示唆しています。小さなファイルが多数存在する環境や、頻繁な更新が行われるデータセットでは、S3 Tablesの自動圧縮機能やトランザクション処理の向上が活きる可能性があります。しかし、今回の検証用のクエリでは、従来のIceberg Tables on Amazon S3の方が優位性を示しました。
現時点では他のサービスとの統合がプレビューであったり、S3 Tablesは比較的新しいサービスであるため、今後のアップデートや最適化によってパフォーマンスが向上する可能性もあります。継続的なモニタリングと再評価が重要となりそうです。
合わせて読みたい









